by Hector Fernandez on Oct 21, 2016

Note: As the ecosystem has developed a lot over the last few years, we moved our user services away from fleet into Kubernetes running on a lightweight underlying fleet layer. However, with recent developments in Kubernetes and lightweight container engines like rkt, we revisited our decision and decided to also migrate our base layer to Kubernetes and thus won’t be using fleet anymore in the future.
Giant Swarm offers a microservices infrastructure on which developers can run their containerized apps. This infrastructure uses multiple open source tools, incl. systemd, CoreOS, etcd, Docker, and many more. However, there is an underlying tool which runs all the infrastructure components and allows us to deploy and manage user applications across our cluster.
This open source tool is called fleet. Fleet is a distributed init system that manages systemd units in a cluster. In other words, fleet is a distributed systemd scheduler that relies on dbus and etcd to coordinate the state of the systemd units in a cluster. The main building blocks of the fleet architecture are the engine (master) and the agents (workers). In this architecture, fleet agents and engines use dbus to talk to systemd to assure the desired state of the systemd units on each node. The fleet engine is in charge of tasks such as the decision making, scheduling, and enforcement of the correct state of the cluster.
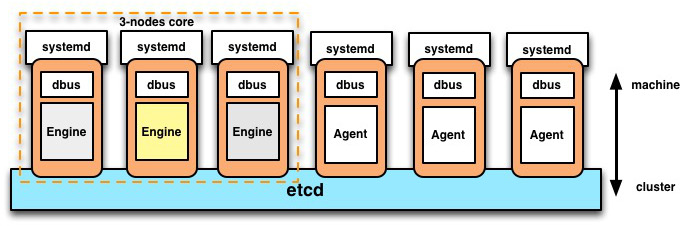
As shown in the the figure above, etcd is used as datastore and coordination mechanism to keep the nodes aware of the cluster’s state. Moreover, this figure shows a fleet cluster composed of 3-nodes as core member(masters) and another group of 3-nodes as workers.
Motivation
At Giant Swarm we use fleet as init system for our core infrastructure. We decided to use fleet because we loved its robustness, intuitive app definitions, and its main functionality of enabling us to manage systemd units in a cluster. Usually our fleet clusters aren’t composed of many nodes (<50), but are expected to handle a non trivial (at this time) amount of units (>3000). The latter is true especially in our first generation infrastructure, where we run user apps with fleet. In that early generation of our infrastructure, the user apps are deployed as systemd unit chains.
As a consequence, our fleet cluster has to handle thousands of units offering good performance and being able to scale on demand. However, we encountered many problems with felet that turned out to be limitations of its current implementation:
- Performance degradation over the time
- Actions over units taking very long times.
- Etcd client can take longer than usual to respond to usual commands such as the set command which can take between 40ms and 1100ms.
- Fleet out of synchronization
- Problems related to unresponsive agents due to socket errors.
- Incoherent fleet
list-units: fleet agents don’t always get the global picture of the cluster’s state.
- Limited scalability (mentioned in fleet documentation)
- This is a known issue that we faced when growing the amount of systemd units as well as the amount of nodes joining a cluster.
- Excessive etcd dependencies: persistent and transient storage
- If etcd misbehaves or is slow then fleet will be affected by it, because it uses etcd as a coordination and datastore system. As an example, more units means more unit states being updated per second, which after some time causes instability (i.e. an update can be very quick (<50ms) but also quite slow (~ 1s)).
- Fail recovery
- If etcd goes down, everything falls apart.
In that direction, we found through testing in our infrastructure that a high workload over etcd induces poor or wrong behavior of fleet. Besides, we believe that the use of etcd to provide inter-process communication for the agents could end up in potential bottlenecks and impact performance negatively.
As a consequence, we started to investigate how to reduce the dependencies on etcd. We aimed to mitigate the scalability issues of fleet, to improve the fail recovery mechanism, and to obtain better throughput (units/sec) and capacity of the fleet cluster.
Why gRPC?
gRPC appeared as a technology which could help us reduce the friction with etcd while providing good performance to coordinate agents with engines. In our modification gRPC represents the new communication layer between the engine and agents. We used gRPC/HTTP2 as a framework to expose all the required operations (schedule unit, destroy unit, save state, etc.) that will allow to coordinate the main engine (the fleet node elected as leader) with the agents. Therefore, we don’t need to use etcd in each node of the cluster to know what to do or to gather the state of the cluster. Agents talk over gRPC to the engine to get the state of the cluster or tasks to be computed. With this new implementation, we also provided a new registry that stores all the information in-memory, thereby the engine doesn’t need to interact with etcd to know how to coordinate the cluster. Etcd is now used only to store persistent data rather than transient data as was the case until now.
Further, we maintained backwards compatibility, keeping the possibility to use etcd to store the coordination mechanism instead of in-memory. All these changes have been merged upstream in the CoreOS fleet repository.
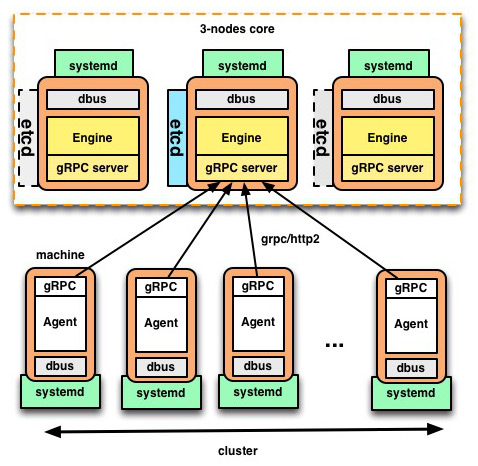
Our new implementation offers a multiplexing layer on top of the former etcd registry used for coordination. This means:
- from the agents’ perspective:
- each time an engine leader change is detected, a gRPC connection to the new leader is established.
- any Registry operation is forwarded (via gRPC) to the leader.
- the engines’ perspective:
- every time a new engine gets “elected” as leader, it starts a gRPC server.
- when an engine loses it’s leadership, it stops the gRPC server, terminating existing connections.
- all the transient data is stored in-memory.
- the persistent data (units, desired state, and schedule) is stored in etcd.
This new implementation is running in our production cluster for quite a while already. We ran experiments in our cluster to validate this new implementation.
Benchmarks
Benchmarks were composed of a CoreOS cluster composed of 3 machines as engines and 4 machines as agents. To highlight the improvements we ran two experiments to evaluate the performance and scalability of the fleet-grpc approach versus the former fleet-etcd one.
How is the performance loading/starting 3k units?
fleet-etcd: 75% of units started in between 1.729 - 28.14 secs. In the following, we show a histogram on which you can better appreciate the completion time to schedule the units.
1.729-28.14 75.5% █████████████████████ 2266
28.14-54.56 6.2% ██ 186
54.56-80.97 2.3% ▋ 69
80.97-107.4 2.43% ▋ 73
107.4-133.8 3.57% █ 107
133.8-160.2 3.53% █ 106
160.2-186.6 2.2% ▋ 66
186.6-213.1 2.17% ▋ 65
213.1-239.5 1.37% ▍ 41
239.5-265.9 0.7% ▏ 21
fleet-grpc: 85% of units started in between 1.004 - 9.907 secs.In the following, we show a histogram on which you can better appreciate the completion time to schedule the units.
1.004-9.907 84.1% █████████████████████ 2522
9.907-18.81 13.6% ████ 407
18.81-27.71 0.0333% ▏ 1
27.71-36.62 0.0667% ▏ 2
36.62-45.52 0.3% ▏ 9
45.52-54.42 0.4% ▏ 12
54.42-63.32 0.433% ▏ 13
63.32-72.23 0.3% ▏ 9
72.23-81.13 0.333% ▏ 10
81.13-90.03 0.5% ▏ 15
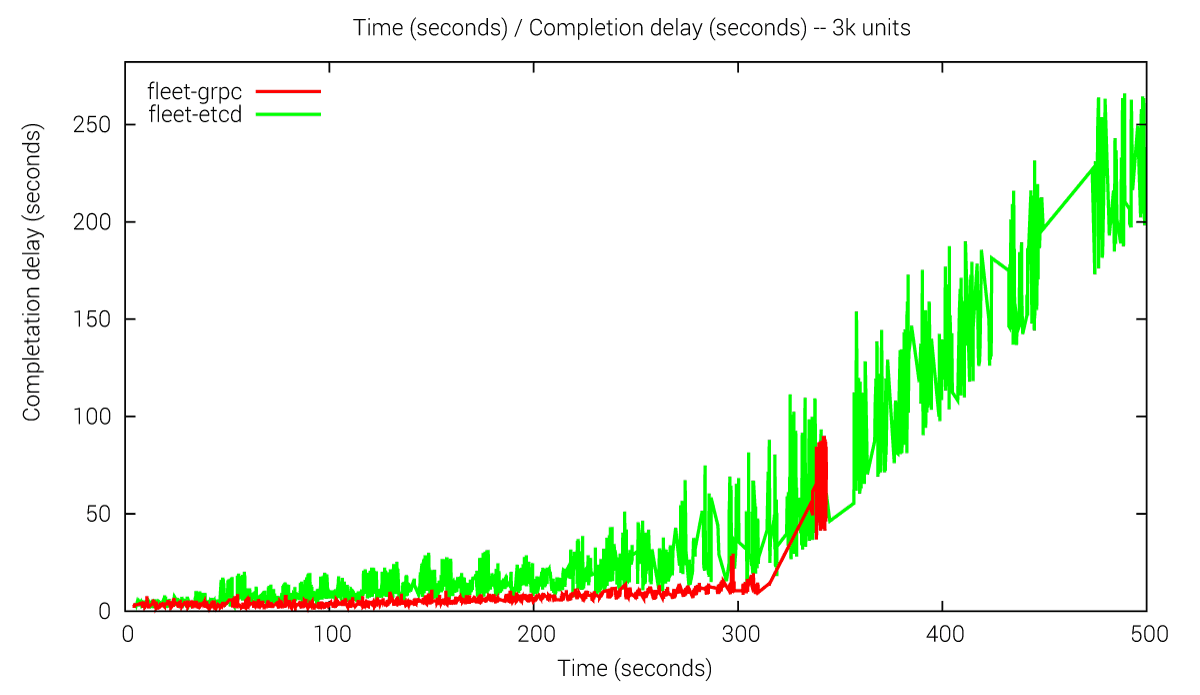
We observe performance issues with the old version when having to handle e.g. 3k units. The grpc approach schedules the units much faster than fleet-etcd. Moreover we can see that the linear complexity is growing, which indicates the scalability issues of the fleet-etcd approach.
Fleet’s threshold in terms of amount of units that can handle:
- fleet-etcd: no more than 3k
- fleet-grpc: up to 20k and beyond
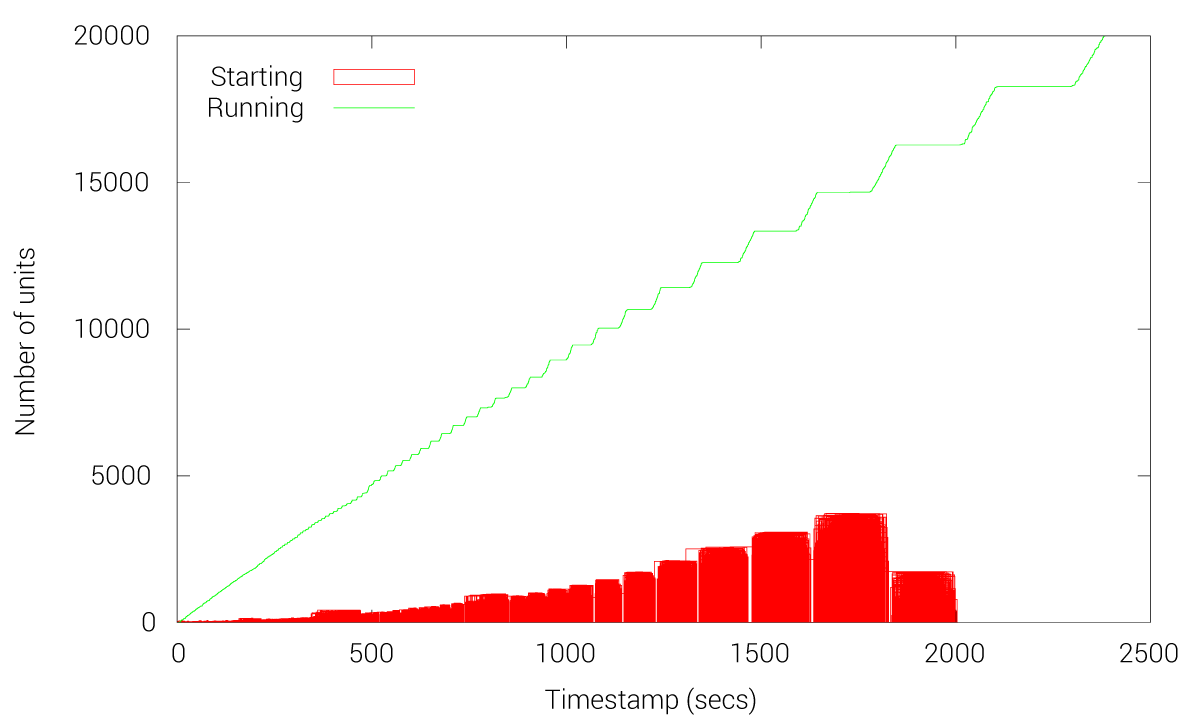
However, we can the time to run 20k units grows linearly due to other fleet issues like an expensive reconciliation loop and cluster state recalculations (operations to periodically learn the state of the cluster). This shows the limits of this new fleet approach but obviously exposes a huge benefit as 20k units can be handled with this new implementation. As mentioned before, with fleet-etcd we cannot handle more than 3k units without starting to experience multiple issues.
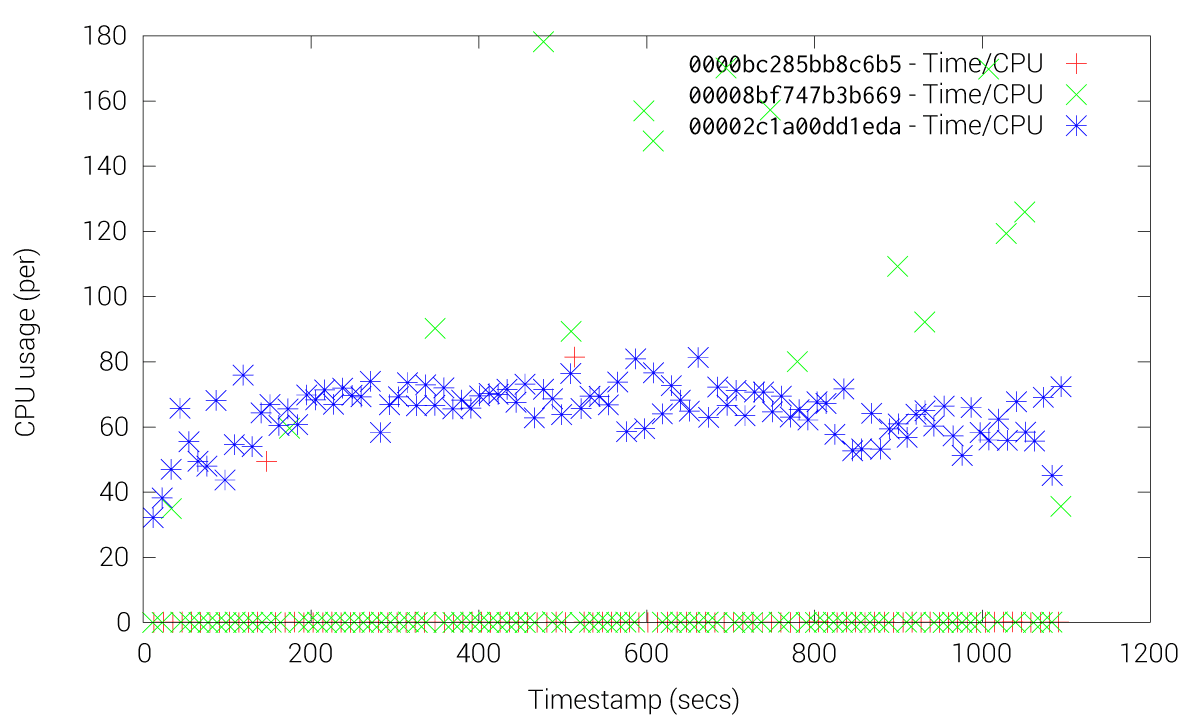
CPU usage of fleet and etcd when using fleet-etcd
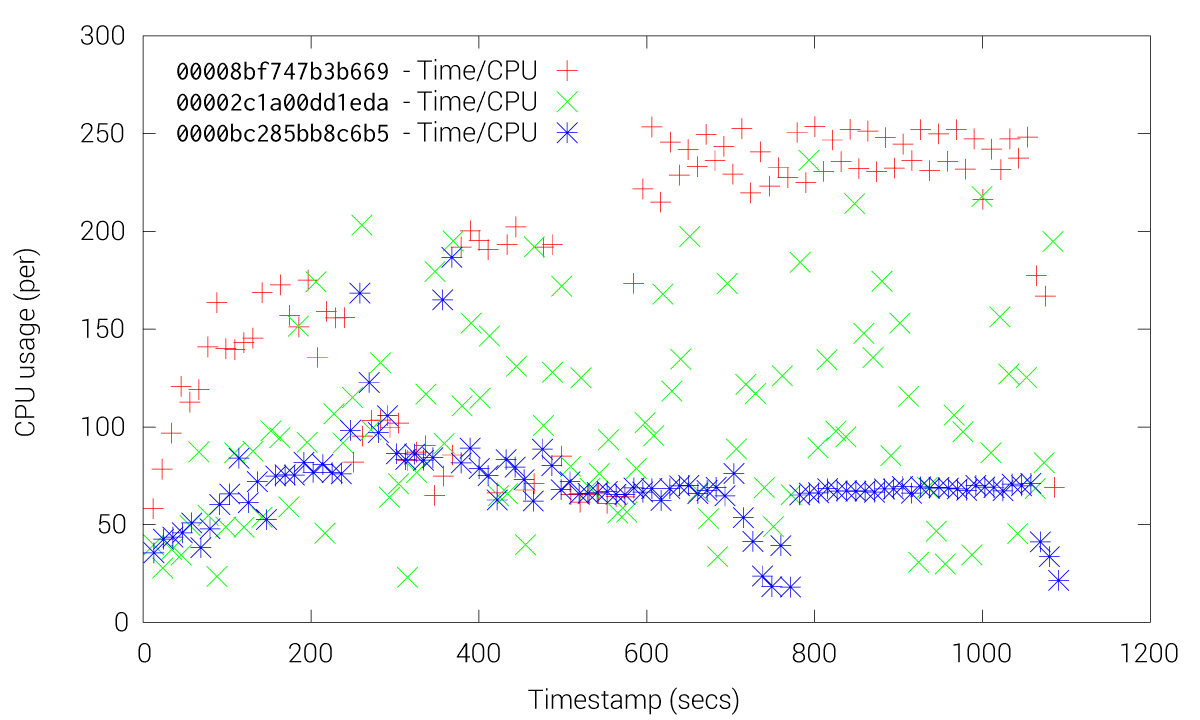
CPU usage of fleet and etcd with the fleet-gRPC
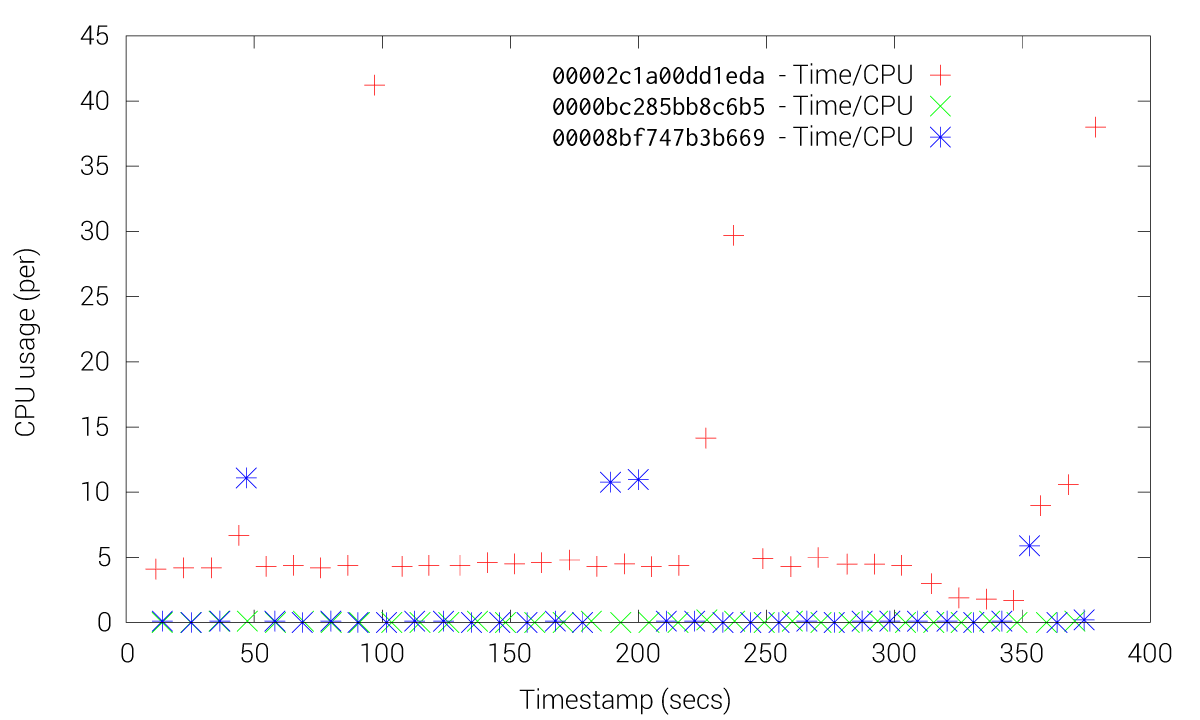
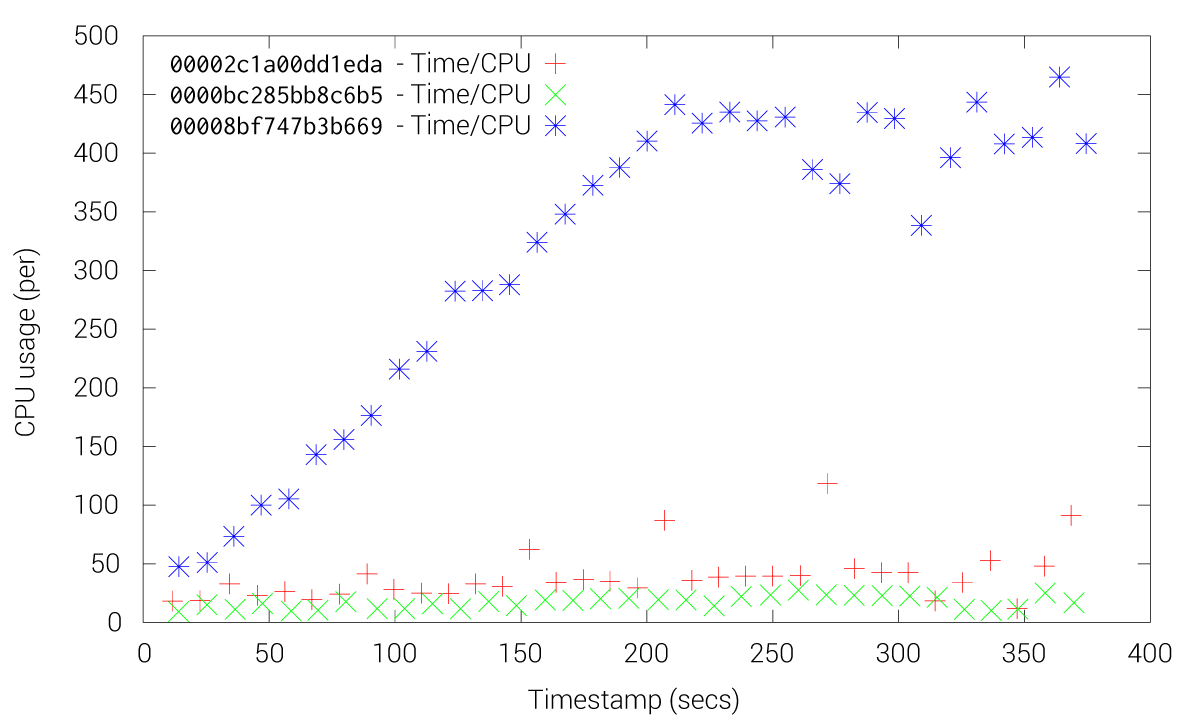
These Figures shows how etcd friction is drastically reduced when using the fleet-grpc approach. With the etcd approach most of the fleet agents and engines experience high CPU usage, especially the engines, while our fleet-grpc approach offers a performance behavior where the fleet engine elected as the leader is the only one with high CPU usage. Accordingly, the fleet-grpc agents have low CPU usage, which saves resources to run user applications on those nodes.
Conclusion
This new implementation of fleet using gRPC offers multiple benefits such as:
- Better throughput
- Less etcd friction
- Lower CPU usage in the fleet agents
- Secure communication (we can use gRPC security mechanisms to ensure that only the right agents talk to the engine).
- Improved scalability
Note: The fleet version used to run the above mentioned experiments contains some additional improvements which we might also push upstream as PRs to the main CoreOS fleet repository. If you want to play around with these changes, you can use the following fleet branch in our forked repository.

Manage Kubernetes Secrets using AWS Secrets Manager
Kubernetes has a built-in feature for secrets management called a Secret. The Secret object is convenient to use, but does not support storing or retr …

Understanding Basic Kubernetes Concepts II - Using Deployments To Manage Your Services Declaratively
This post is the second in a series of blog posts about basic Kubernetes concepts. In the first one I explained the concepts of Pods, Labels, and Repl …

Securing the Configuration of Kubernetes Cluster Components
In the previous article of this series Securing Kubernetes for Cloud Native Applications, we discussed what needs to be considered when securing the i …