by Puja Abbassi on Feb 25, 2016

On Tuesday we showed you how you can simulate CoreOS clusters on a single machine with Onsho. We also mentioned that we are working on improving fleet to make it more performant for use in highly scalable microservice infrastructures. The fleet PR is a first effort to merge the changes we made to our internal fork of fleet upstream.
When working on performance improvements, you need to test if your changes actually did improve the performance. As we couldn’t find a benchmarking tool for fleet out there, we decided to build our own. Enter Nomi, a simple tool to benchmark and stress test fleet clusters.
Nomi lets you define benchmarks using a simple YAML definition. Based on that it deploys units to your fleet cluster, measuring delays in start and stop times as well as CPU load of fleetd and systemd per host. You can choose raw systemd units (to measure raw fleet performance) or let Nomi deploy standard Docker or rkt containers (based on alpine). Latter will let you stress test your cluster with the different container engines to show up eventual bottlenecks that might occur when using Docker or rkt.
Benchmarking Fleet
The easiest way to run a benchmark with Nomi is using its Docker image on one of your fleet cluster nodes.
docker run -ti \
-v $PLOTS_DIR:/nomi_plots \
-v /var/run/fleet.sock:/var/run/fleet.sock \
--net=host \
--pid=host \
giantswarm/nomi:latest \
run \
--addr=192.68.10.101:54541 \
--generate-gnuplots \
--raw-instructions="(sleep 1) (start 10 100) (sleep 60) (stop-all)"
Be sure to give the Docker container the IP and port of your host using the -addr parameter.
In the above example we are using the --raw-instructions parameter to run Nomi with a simple set of benchmark instructions. For more complex instructions you can use YAML files to specify benchmarks. For example:
instancegroup-size: 1
instructions:
- start:
max: 8
interval: 200
- expect-running:
symbol: <
amount: 10
- sleep: 10
- start:
max: 3
interval: 300
- sleep: 200
- stop: stop-all
Collecting And Showing Metrics
Once Nomi is running it will collect metrics including delays in starting and stopping of units in the cluster as well as CPU usage of fleetd and systemd for each cluster node. We measure only CPU resource usage as these tools are rather CPU-intensive.
After the benchmark has finished Nomi will output the gathered data. By default, it prints a histogram to stderr that shows the delay of units when starting in the cluster.
1.249-8.583 48.9% █████████████████████ 440
8.583-15.92 21.2% ████████▋ 191
15.92-23.25 4.89% ██ 44
23.25-30.59 4.22% ██ 38
30.59-37.92 5.22% ██ 47
37.92-45.25 4.78% ██ 43
45.25-52.59 4.56% ██ 41
52.59-59.92 3.33% ██ 30
59.92-67.26 2.11% ▉ 19
67.26-74.59 0.778% ▍ 7
Additionally, you can choose out of three output types. First, you can dump the whole metrics as a JSON file to stdout, so that you can then use that to analyze or visualize to your liking. Second, you can dump into a tarred HTML/javascript file that uses d3.js to visualize the benchmarks.
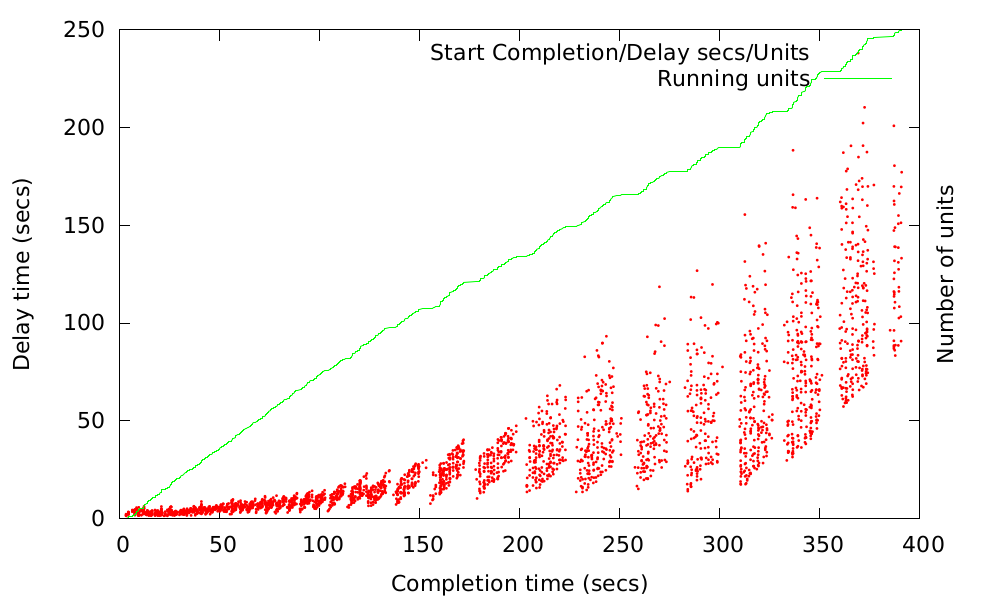
The third option is to generate gnuplots. For this you need gnuplot support on your system or use the Docker container like in the example above. Nomi comes with several plots including delay plots of start and stop operations, and CPU usage plots of fleetd and systemd for all cluster nodes. Additionally, you can generate your own customized plots based on the metrics gathered.
Get Your Cluster Up And Test
If you are using fleet anywhere in your infrastructure (no matter if on CoreOS or any other Linux distribution) you should try this tool out. Check out the GitHub repo for details. You can try out different fleet versions and benchmark them against each other. Changing out your fleet version is especially easy with Yochu. You can also measure performance differences with different container engines, like rkt or Docker, under stress.
If you are not using fleet, yet, you should try it out with our previously released CoreOS provisioning tools. You can use Kocho for quickly provisioning CoreOS clusters with fleet on AWS. Alternatively, use Mayu to either get a bare metal cluster running, or setup a local test environment in combination with Onsho.
Check it out and tell us what you think in the comments below, on HackerNews, IRC (#giantswarm), or our mailing list.

Replicate A Whole Data Center Locally With Onsho
Two weeks ago we introduced Mayu and Yochu, a set of tools to set up customized CoreOS clusters on bare metal, available as open source. However, not …

Meet Kocho - Our Bootstrapping Tool For CoreOS Clusters On AWS
Last week we made Mayu and Yochu, a set of tools to set up customized CoreOS clusters on bare metal, available as open source. Today we are introducin …

Enter Mayu & Yochu – Our Provisioning Tools For CoreOS On Bare Metal
Despite the ongoing growth of the public cloud market we see more and more companies operating their own bare metal. These are not only big tech compa …